Outils de corpus
Corpus — 6
clement.plancq@ens.fr
Étiquetage et étiqueteurs
L’étiquetage morpho-syntaxique (POS tagging) consiste à assigner des informations grammaticales à chaque mot d’un texte.
entrée
Je suis allée dans la chambre. Elle me cherche alors je la chambre.
sortie
Je/PRO suis/V allée/V dans/PP la/DET chambre/N. Elle/PRO me/PRO cherche/V alors/ADV je/PRO la/PRO chambre/V.
Les étiqueteurs sont souvent couplés à un outil de segmentation en phrases et en mots et/ou à un lemmatiseur.
Difficultés
Eugene Charniak. Statistical techniques for natural language parsing. 1997
90% de précision globale (accuracy) avec un algo simpliste sur de l’anglais
- Mot connu -> tag le plus fréquent
- Mot inconnu -> nom propre
Aujourd’hui les meilleurs étiqueteurs sur le Penn Treebank frôlent les 98% (sota)
Mais les résultats descendent à 90% sur des données issues de Twitter (voir http://nlpprogress.com/english/part-of-speech_tagging.html)
Difficultés
- Ambiguïté
la/PRO/DET/N chambre/N/V est/V/N bien/A/ADV/N exposée/A/V
- Mots inconnus
Noms propres, mots étrangers, sigles. Quelle étiquette associer ?
- Ressources
Peu de corpus annotés de référence (gold standard) en français
Difficultés /2
L’étiquetage est surtout une tâche de disambiguïsation
Pourtant la plupart des types formant le vocabulaire sont non ambigus : ils ne peuvent porter qu’une catégorie morpho-syntaxique
Mais les mots ambigus sont les plus fréquents dans les textes
 extrait de Speech and Language Processing (3rd ed. draft). Dan Jurafsky and James H. Martin
extrait de Speech and Language Processing (3rd ed. draft). Dan Jurafsky and James H. Martin
Etiqueteurs pour le français
Beaucoup d’outils
- Cordial analyseur (Synapse) : propriétaire, payant
- TreeTagger : propriétaire, gratuit
- MElt : open source (LGPL)
- SEM : open source (MIT)
- LIA_TAGG : open source (GPL)
- MarsaTag : libre
- Talismane : open source (Affero GPL)
- Standford POS Tagger : open source (GPL)
- Stanza : open source (Apache)
- Spacy : open source (MIT)
- …
Etiqueteurs pour le français
Peu de modèles
La plupart des modèles utilisés par ces étiqueteurs ont été entraînés sur le French Treebank
On trouve peu de modèles librement distribués pour l’oral ou d’autres variétés du français. Il existe un modèle au format TreeTagger pour le français médiéval : voir BFM
Il existe un modèle Talismane pour les textes littéraires en français moderne
Types d’étiqueteurs
- À base de règles
- Apprentissage par correction (Brill)
- Méthodes probabilistes
- Méthodes neuronales
Etiqueteurs à base de règles
Utilisation d’un lexique (forme fléchie, POS, morpho, lemme) et de grammaires locales (ex: Unitex)
- Avantages :
- règles lisibles et modifiables aisément
- implémentation simple et efficace (automates finis)
- Inconvénients :
- écriture manuelle de règles : difficile et couteux
- peu de performance sur les mots inconnus et les entrées bruitées
Plus très utilisés aujourd’hui
Apprentissage par correction
Étiqueteur de Brill
Eric Brill. 1992. A simple rule-based part of speech tagger. In Proceedings of the third conference on Applied natural language processing (ANLC ’92). Association for Computational Linguistics, Stroudsburg, PA, USA, 152-155. DOI=http://dx.doi.org/10.3115/974499.974526
Apprentissage fondé sur des transformations (Transformation-based error-driven learning), guidé par les erreurs
Se veut être une alternative aux étiqueteurs stochastiques
Apprentissage par correction
Étiqueteur de Brill
- Nécéssite un corpus annoté de référence (Brill a utilisé le Brown Corpus)
- 90% pour le dictionnaire/modèle
- 5% pour construire la base de règles
- 5% pour les tests
Etiqueteur de Brill
Phase 1 : pas de prise en compte du contexte
Tag de chaque mot avec tag le plus probable d’après le modèle, sans prise en compte du contexte
Les mots inconnus du corpus d’entraînement avec capitale sont taggés noms propres
Les autres mots inconnus du training reçoivent le tag le plus fréquent des mots finissants avec les mêmes trois lettres (ex: blahblahous est taggué adjectif)
Beaucoup d’erreurs à l’issue de cette phase
Etiqueteur de Brill
Phase 2 : corrections
Les erreurs de tagging à l’issue de la phase 1 sont conservées
- Application de patrons de correction (règles contextuelles) sur les erreurs. Ex tag a devient b si:
- le mot précédent est taggé z
- le mot suivant est taggé z
- le mot précédent est taggé z et le mot suivant w
- etc…
- le mot précédent est taggé z
Etiqueteur de Brill
Phase 2 : corrections
Exemple de règle apprise à l’aide d’un patron de correction
changer l'étiquette de Déterminant en Pronom si le mot suivant est un Verbe conjuguéCalcul du nombre d’erreurs corrigées avec la règle et le nombre d’erreurs générées : si la règle est rentable elle est conservée dans une base de règles et appliquée sur l’ensemble du corpus
Etiqueteurs probabilistes
- Les plus courants
- Très performants et ne nécessitent pas d’expertise
- Besoin d’un corpus annoté de référence de grande taille
- Les chaînes de Markov sont au cœur de la plupart des algos utilisés
- Nombreuses variantes possibles (entropie maximale, SVM, CRF, …)
Performance améliorée lorsque le modèle probabiliste est couplée à un lexique
Les erreurs sont difficilement analysables
TreeTagger
Un des plus utilisés pour le français
- Pas forcément le meilleur, propriétaire mais :
- gratuit
- rapide
- nombreux modèles disponibles
On ne sait presque rien des données utilisées pour apprendre le modèle du français
Helmut Schmid (1994): Probabilistic Part-of-Speech Tagging Using Decision Trees. Proceedings of International Conference on New Methods in Language Processing, Manchester, UK.
TreeTagger
La plupart des étiqueteurs probabilistes reposent sur des ngram utilisés pour modéliser la probabilité d’une séquence de mots taggués.
TreeTagger repose également sur des ngram mais il utilise des arbres de décision binaires pour estimer les probas de transition entre les mots de la séquence.
TreeTagger
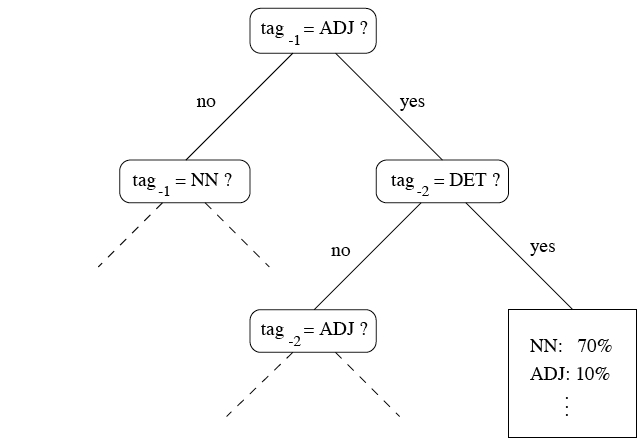
TreeTagger
Pour les mots inconnus TreeTagger s’appuie sur des probas de suffixes
istes NOM 0.7 ADJ 0.2 VERB:pres 0.1Les tests de l’arbre de décision sont choisis pour avoir le partitionnement le plus efficace possible
Vous trouverez une bonne illustration dans le support de Franck Sajous iciSelon les algorithmes on va utiliser des méthodes différentes pour évaluer l’efficacité du partionnement. TreeTagger utilise la méthode du gain d’information basée l’entropie.
Voir le cours de Loïc Grobol pour plus de détails.
Évaluation
Les étiqueteurs à l’état de l’art obtiennent des scores de précision globale (accuracy) > 95%
Pour être évalué, le résultat d’un taggeur automatique est comparé à un corpus annoté de référence (gold standard)
Pour un taggeur on met en avant la précision : \[ \frac{nombre\ d'unités\ correctement\ annotées}{nombre\ d'unités\ annotées} \]
Évaluation en recherche d’information
- Rappel \[ \frac{nombre\ d'éléments\ pertinents\ retrouvés}{nombre\ d'éléments\ pertinents} \]
\[ \frac{tp}{tp+fn}\]
- Précision \[ \frac{nombre\ d'éléments\ correctement\ retrouvés}{nombre\ d'éléments\ retrouvés} \]
\[ \frac{tp}{tp + fp} \]
Évaluation
- Précision par POS
macro-average \[ \frac{Pr_N + Pr_V + Pr_A}{3} \]
micro-average \[ \frac{tp}{tp + fp} \]
- F-mesure compromis rappel-précision utlisé pour évaluer la pertinence du système \[ F_1=2\times\frac{precision \times rappel}{precision+rappel} \]